
這幾天的文章會是一系列的,會需要一起看才比較能看懂整個ML模型的輪廓,
然而因為一天能寫的內容量有限,所以我會在前言部分稍微說明我寫到哪。
因為ML模型的訓練階段章節內容會分很多部分,我們要先確認好自己在哪個階段,
以免吸收新內容卻不知道用在內容的什麼地方。
★ML的整個「訓練過程」:這裡以監督式學習(Supervised Learning)為例
| 階段 | 要做的事情 | 簡介 |
|---|---|---|
(訓練前) |
決定資料集與分析資料 | 你想要預測的是什麼資料? 這邊需要先知道 example、label、features的概念。介紹可參考:【Day 15】,而我們這次作為範例的訓練資料集介紹在【Day 19】。 |
(訓練前) |
決定問題種類 | 依據資料,會知道是什麼類型的問題。regression problem(回歸問題)? classification problem(分類問題)? 此處可參考:【Day 16】、與進階內容:【Day 17】 |
(訓練前) |
決定ML模型(ML models) | 依據問題的種類,會知道需要使用什麼對應的ML模型。回歸模型(Regression model)? 分類模型(Classification model)? 此處可參考:【Day 18】,神經網路(neural network)? 簡介於:【Day 25】 |
| (模型裡面的參數) | ML模型裡面的參數(parameters)與超參數(hyper-parameters) 此處可參考:【Day 18】 |
|
(訓練中) 調整模型 |
評估當前模型好壞 | 損失函數(Loss Functions):使用損失函數評估目前模型的好與壞。以MSE(Mean Squared Error), RMSE(Root Mean Squared Error), 交叉熵(Cross Entropy)為例。此處可參考:【Day 20】 |
(訓練中) 調整模型 |
修正模型參數 | 以梯度下降法 (Gradient Descent)為例:決定模型中參數的修正「方向」與「步長(step size)」此處可參考:【Day 21】 |
(訓練中) 調整腳步 |
調整學習腳步 | 透過學習速率(learning rate)來調整ML模型訓練的步長(step size),調整學習腳步。(此參數在訓練前設定,為hyper-parameter)。此處可參考:【Day 22】 |
(訓練中) 加快訓練 |
取樣與分堆 | 設定batch size,透過batch從訓練目標中取樣,來加快ML模型訓練的速度。(此參數在訓練前設定,為hyper-parameter)。與迭代(iteration),epoch介紹。此處可參考:【Day 23】 |
(訓練中) 加快訓練 |
檢查loss的頻率 | 調整「檢查loss的頻率」,依據時間(Time-based)與步驟(Step-based)。此處可參考:【Day 23】 |
(訓練中) 完成訓練 |
(loop) -> 完成 | 重覆過程(評估當前模型好壞 -> 修正模型參數),直到能通過「驗證資料集(Validation)」的驗證即可結束訓練。此處可參考:【Day 27】 |
(訓練後) |
訓練結果可能問題 | 「不適當的最小loss?」 此處可參考:【Day 28】 |
(訓練後) |
訓練結果可能問題 | 欠擬合(underfitting)?過度擬合(overfitting)? 此處可參考:【Day 26】 |
(訓練後) |
評估 - 性能指標 | 性能指標(performance metrics):以混淆矩陣(confusion matrix)分析,包含「Accuracy」、「Precision」、「Recall」三種評估指標。簡介於:【Day 28】、詳細介紹於:【Day 29】 |
(訓練後) |
評估 - 新資料適用性 | 泛化(Generalization):對於新資料、沒看過的資料的模型適用性。此處可參考:【Day 26】 |
(訓練後) |
評估 - 模型測試 | 使用「獨立測試資料集(Test)」測試? 使用交叉驗證(cross-validation)(又稱bootstrapping)測試? 此處可參考:【Day 27】 |
| (資料分堆的方式) | (訓練前) 依據上方「模型測試」的方法,決定資料分堆的方式:訓練用(Training)、驗證用(Validation)、測試用(Test)。此處可參考:【Day 27】 |
而今天的文章我們就要來介紹所謂的損失函數(Loss Functions)的概念。
第三章節的課程地圖:(紅字標記為本篇文章中會介紹到的章節)
Optimization
Introducing Loss Functions
課程地圖
在前面的章節中,我們定義的ML模型內的參數 parameters 與 hyperparameters,
並介紹了 linear models 裡面的 parameters 大概會做什麼運算。
然後我們就要討論如何去最佳化這些在ML模型中的parameters,
在【Day 19】 中,我們曾經提過在數據集不大時,可以使用的統計方法。
後來我們提到可以在參數空間(parameter space)試著搜尋最佳參數,
但要「比較每個參數的好壞」,我們會需要一個「判定的準則」。
今天我們就是要來細講這個「判定的準則」,
我們稱這個準則為損失函數(loss functions),
這個函數就是用來幫助依照現在ML模型(裡面參數parameters)的預測結果,
做好壞的評估,並且他會以「數值化」的方式告訴我們有多好/壞。
regression problems(回歸問題) 的損失函數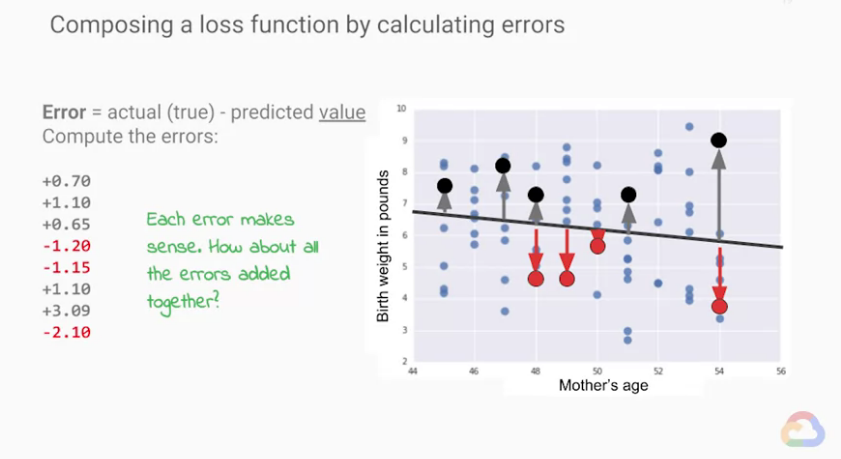
我們將目前所預測的值(prediction)與真實數據(label)直接比較差多少,
我們稱之為「誤差(error)」,我們可參考上圖。
但在每次訓練中,我們有非常多組參考資料(example),
我們會得到一堆誤差(error),
我們需要去思考該怎麼組合這些數據。
然而,我們想一個問題,如果直接加總的話,正值與負值會被抵銷,
例如誤差組合:(+100,-100)與(0,0),sum值相同,但代表意義相同?!
顯然,這方法存在問題。
因此,為了解決上述問題,我們應該要找一個更具代表性的
能象徵我們預測的值(prediction)與真實數據(label)的算法,
而這算法不會使得「誤差(error)」之間相互抵消。
error)」的絕對值之和呢?這方法稱作
MAE(Mean absolute error)- 平均絕對值誤差,這方法是合理的,
但會有「在等於0時」不可微分的問題(這個可以自己畫圖或看以下參考資料)
不可微分會有什麼問題? 簡單來說,我們會沒辦法透過微分決定ML模型的修正方向。
但完全不能使用嗎? 倒也不完全是不能用,他有它的長處,但這邊再談下去就太多了,
★就留個可參考的資料給有興趣的人:機器/深度學習: 基礎介紹-損失函數(loss function)
MSE(Mean Squared Error)
MSE(Mean Squared Error)的算法是從我們的所有數據中,
MSE方法計算結果是很值得參考的,確實很適合作為我們的 loss function。
但MSE方法仍然有個小問題,在「單位的解釋」上我們有點難以解釋數據。
例1:計算「體重」誤差,請問「公斤的平方」意義是?
例2:計算「金錢」誤差,請問「美元的平方」意義是?
因此,我們會採用MSE(Mean Squared Error)的平方根,
RMSE(Root Mean Squared Error) 以獲得我們能解釋的單位。自己的註:
注意:
MSE(Mean Squared Error)在「數值」上仍然具有誤差代表性,並非不能使用。
而使用RMSE(Root Mean Squared Error)只是更能解釋「數值」量的意義(因為有單位)。

(RMSE的算法,少做開根號的動作即為MSE。)
(圖中ŷ表示我們預測的值(predictd value)、y表示真實數據(labeled value))
當RMSE(Root Mean Squared Error)的數值越大,同時也能表示我們預測的表現越差。
所以訓練我們要做的事情就是「最小化RMSE(Root Mean Squared Error)」。
現在我們找到了一個方法,能幫助我們在參數空間(parameter space)中衡量參數(parameter)的好壞。
記得:參數(parameter)使用於我們的ML模型中,也就是我們線性模型(linear model)中的參數。
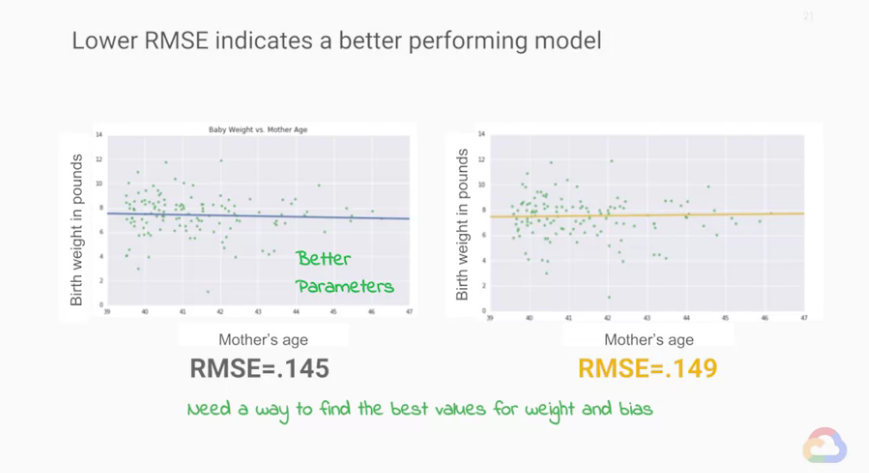
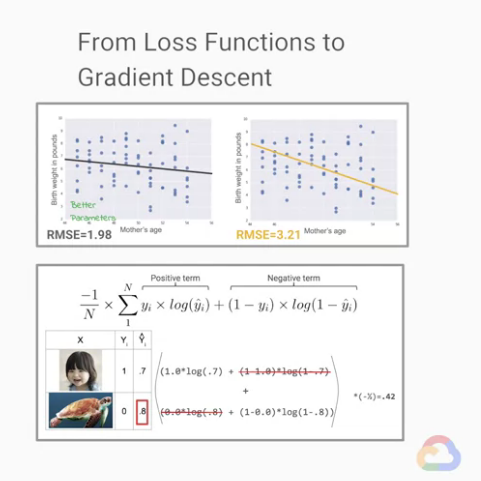
我們稍微比較上面的的兩張圖,這是兩張散佈圖(資料集為【Day 19】的嬰兒資料),
我們只看39歲以上的母親並畫上回歸線,
視覺上我們非常難看出哪條線畫的比較好。
這就是為何我們要決定我們的損失函數(loss functions),
他可以數值化且具體的指出哪一條線比較好,
於是我們使用我們剛剛決定的損失函數(loss functions):RMSE(Root Mean Squared Error)
我們發現左邊的模型目前的RMSE值為145、右邊的模型目前的RMSE值為149,
因此,透過損失函數(loss functions)我們知道左側的「目前模型訓練的結果比較好」。
「目前模型訓練的結果比較好」:表示有較好的
weight與bias。
classification problems(分類問題) 的損失函數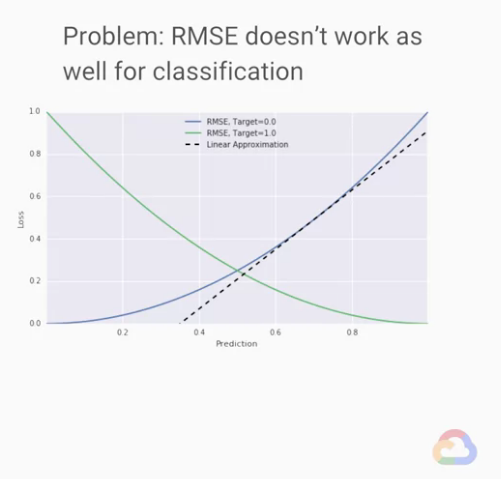
(用RMSE預測分類問題的結果。下方內容有圖片解釋。)
但我們發現有個問題:RMSE作為損失函數(loss functions),
在線性回歸問題(linear regression problems)的表現很好,
在分類問題(classification problems)似乎不行。
我們先回到分類問題的本身,還記得當初我們定義的分類問題,
他的結果是將目標分類。也就是我們的label會是一個「類別」而「非連續數」。
我們拿之前提到的編碼(encode)為例,
透過編碼(encode),我們能將我們預測的類別以「0或1」的方式表示。
我們回來解釋上方的圖,
label)的RMSE誤差這曲線出了什麼問題呢?
我們可以看見當目標target(
label)為0時,預測結果1的比預測結果0.5的糟糕三倍
這邊比較難懂,自己稍微補充解釋一下:
例如明明是正確結果是0,我們預測1,loss自然就是全錯 = 1
明明是正確結果是0,我們預測0,loss自然就是全對 = 0
明明是正確結果是0,我們預測0.5,loss是「算誤差總共的RMSE」約等於 0.3
(很多的「0.5-0」然後平方、除總數、開根)
這也是為什麼明明是正確結果是1,我們預測0.5,loss是也等於 0.3
因為也是(很多的「0.5-1」然後平方、除總數、開根),一樣吧!
這結果說明了什麼? 有些糟糕的預測應該有更強的懲罰,而且這預測完全不夠直覺。
所以證明我們會需要一個新的損失函數(loss functions),
針對我們的classification problems(分類問題)能夠有更直覺的懲罰。
(自己的註:「直覺的懲罰」的概念要比較下圖比較好懂,下面會解釋。)
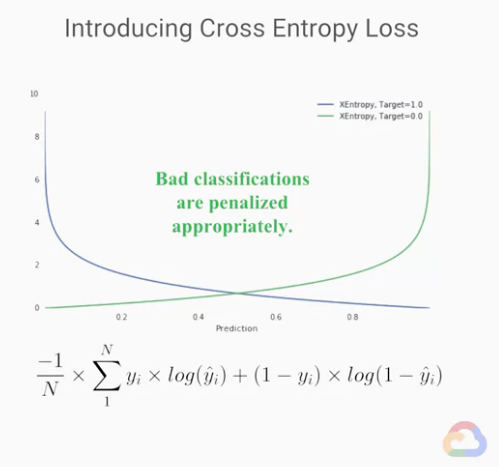
交叉熵(Cross Entropy)是最常使用於分類問題的損失函數(loss functions)。
交叉熵(Cross Entropy)又有個別名log loss
上圖我們做一個與用「RMSE預測分類問題」的結果類似的圖,
我們使用交叉熵(Cross Entropy)做為新的損失函數(loss functions)。
特別注意:圖中顯示
交叉熵(Cross Entropy)會強烈處罰錯誤的預測。
這邊比較難懂,自己稍微補充解釋一下:
與上圖比較中,如果以藍線來說(真實label為1),預測結果如果是0,
看藍色取線的左側,套一句【Day 17】的內容,有沒有一種預測錯就非常完蛋的感覺?
與上面RMSE相比,處罰嚴重太多了,分類問題正是需要在分類錯誤時有最嚴重的懲罰,
我之前所說的「分類正確沒事,分類錯誤非常完蛋!!! 只要有分錯邊,誤差瘋狂上升」,正是類似這樣的概念~。
★ 均方差(mean squared error) 與 交叉熵(cross-entropy) 的比較★
| 常用的計算誤差方法 | 均方差(mean squared error) | 交叉熵(cross-entropy) |
|---|---|---|
| 使用問題種類 | regression problem(回歸問題) |
classification problem(分類問題) |
| 訓練目標 | 最小化「均方差」 | 最小化「交叉熵」 |
| 一維畫線(解)依據 | 只要能使最小距離就好(平方最小) | 線畫下去就是要分好兩類資料,不可以有人跑錯邊(誤差會指數成長) |
| 我自己的理解方式(不完全正確) | 計算距離,所以不管在線的哪邊沒差,離線平均都近一點就能最小惹 | 分類正確沒事,分類錯誤非常完蛋!!! 只要有分錯邊,誤差瘋狂上升 |
完整內容請參考:【Day 17】 Google ML - Lesson 3 - 多維度線性回歸解(N-D Regression), 交叉熵(cross-entropy)與均方差(MSE) 作為誤差函數計算所帶來的不同
我們下面來舉一個實際的例子。

上面這個就是交叉熵(Cross Entropy)的公式,
簡單拆解一下我們可以說分成「兩大terms」,
有趣的是這個公式每次「只會有一個term」有反應。
自己的註:「反應」等於「會產生loss的值」
Positive term:當結果是1時有反應。Negative term:當結果是0時有反應。你問為什麼嗎? 自己的註:
因為「0乘任何東西都是0,在Positive term出現
0相乘就沒反應了。」
然後也是因為「0乘任何東西都是0,在Negative term出現1相乘就沒反應了(因為1-1=0)。」

這裡我們有一張表,正是一個圖片分類的問題,它秀出兩種已經被encode的labels,
這裡的encode方法為「有人臉的為1,沒有人臉的為0」
並且有我們的預測結果(predictions)與實際結果(label),看目前預測的結果似乎不錯。

我們先看上方的example,因為它真的是人臉,所以label=1,
而我們預測0.7,我們發現後面的Negative term消失了(因為1-1=0),
而只剩下 Positive term 提供 loss。
我們在看下方的example,因為它不是人臉,所以label=0,
而我們預測0.7,我們發現前面的Positive term消失了(因為0乘任何東西都0),
而只剩下 Negative term 提供 loss。
稍微計算一下結果,我們得到的Cross Entropy Loss = 0.13
似乎是不錯的數值,顯示我們的模型結果不錯,然而我們來做個比較會更明顯。

如果我們的模型沒有訓練好(做出好的預測),結果會是多少?
我們將下方的預測結果改為 0.8,也表示著下方結果目前是被錯誤預測(分類)的,
我們計算Cross Entropy Loss = 0.42,Loss有增加,
別忘了我們的訓練目標是要將「最小化Loss」,
所以確實增加的Loss不是接近我們要的訓練結果。
因此,上面介紹的方法就是我們如何在參數空間(parameter space)中比較參數的好壞,
自己再註一下:參數(parameter)指的就是
weight與bias
不論是使用 RMSE(Root Mean Squared Error) 作為回歸問題的Loss Functions,
或是使用 交叉熵(Cross Entropy) 作為分類問題的Loss Functions,
要記住我們的目標是找出最佳的參數,Loss Functions是我們參考好壞的依據,
但知道如何衡量好壞後,接下來我們要講的是如何去尋找這些點?
這個我們會在下一章梯度下降法 (Gradient Descent)提到。
coursera - Launching into Machine Learning 課程
medium - 機器/深度學習: 基礎介紹-損失函數(loss function)
medium - Understanding binary cross-entropy / log loss: a visual explanation
若圖片有版權問題請告知我,我會將圖撤掉
